参考基因组知识汇总
基因组大小
- 人类基因组主要由细胞核的23对染色体组成(核基因组),还包括线粒体中的小DNA分子(线粒体基因组)。
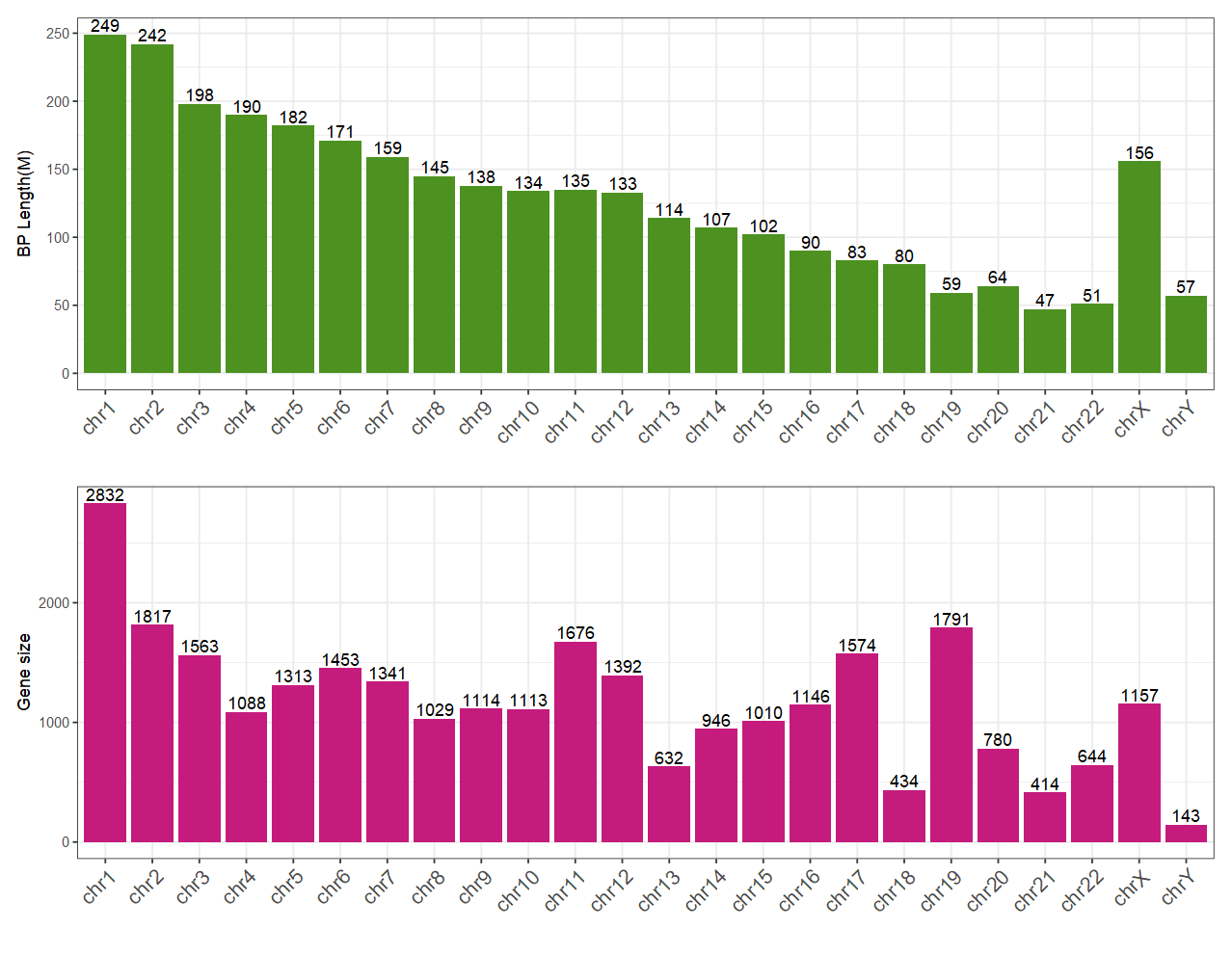
- 单倍体基因组大概有30亿个碱基对组成,具体到每个染色体的碱基对长度与基因数量可见下图:
- 在这30亿个碱基中,仅有1.5%的区域是2~3w个可编码蛋白质的基因。
- 平均基因长度有10Kbp左右,但是不同基因的长度区别很大
- 其余98.5%的区域为非编码区,包括各种调控基因表达的DNA原件,同时也可以转录为non-coding RNA,发挥潜在作用。
参考基因组和基因组注释
参考基因组与基因组注释的关系
自从 1990 启动的家喻户晓的人类基因组计划开始,全世界的科学家竭尽全力破译了第一个完整的人类基因组,从那时开始人类拿到了一本只有 ATCG 四个碱基书写的天书。后续人们逐步完善了基因组序列信息,并写在 Fasta 格式的文本文件“天书”中,这本天书就叫做参考基因组。
科学家利用实验手段解析大量的基因和非编码序列,这些序列被标记在参考基因组的位置上,同时加入了大量的注释信息,最终写成了 BED,GTF等不同格式的注释文件。因此,基因组注释文件就把基因序列和基因功能联系起来。
随着时间的推移,在更先进技术的加持下,在已经构建好的基因组和注释信息上不断增加,删减,修改,就有了不同的版本。每个版本的参考基因组都对应相应的基因组注释文件。
基因组版本命名
为了更加准确的构建标准参考基因组,NCBI,EBI,桑格研究所等机构共同组建了参考基因组联盟(Genome Reference Consortium)。GRC 利用最佳的技术装配,纠正,增加基因组序列,以此作为在生信分析领域作为参考的基因组。目前,该机构构建了人,小鼠,大鼠,斑马鱼,鸡的参考基因组。
人的参考基因组官名叫 GRCh38 (Genome Reference Consortium Human Build 38),GRCh38 在UCSC基因组浏览器中还有个小名 hg38,这个小名对于大多数人来说是更亲切熟悉的。GRCh38 在 GenBank 中叫 GCA_000001405.15,在 RefSeq 中叫 GCF_000001405.26,虽然 GRC 组织建议在所有出版物和工具中使用该编号,但事实是前两种 GRCh38 和 hg38 对生信分析更常见。在不更改染色体坐标的情况下,向参考基因组添加或替换新序列,这种打补丁的方式,会在基因组版本后加 .p (patch)来命名。如果有大的基因组位置变动,则是大版本的更新,我们一般体到的hg19和hg38就是这种情况。
常用的人和小鼠参考基因组对应列表如下:
| 发布时间 | 2013 | 2009 | 2006 |
|---|---|---|---|
| GRC 官名 | GRCh38 | GRCh37 | GRCh36 |
| UCSC | hg38 | hg19 | hg18 |
| Ensemble | GRCh38 | GRCh37 | GRCh36 |
| GENCODE | 38 | 19 | 3c |
| NCBI | GRCh38 | GRCh37 | GRCh36 |
| GenBank | GCA_000001405 | ||
| RefSeq | GCF_000001405 |
| 发布时间 | 2020 | 2011 | 2007 |
|---|---|---|---|
| GRC 官名 | GRCm39 | GRCm38 | |
| UCSC | m39 | mm10 | mm9 |
| Ensemble | GRCm39 | GRCm38 | |
| GENCODE | M27 | M25 | M1 |
| NCBI | GRCm39 | GRCm38 | NCBIM37 |
参考基因组文件
人类基因组序列信息通常以染色体为单位保存为fasta文件中。
- 参考基因组一般保存为纯文本格式,即直接记录“A”、“T”、“C”、“G”这样的 ASCII 码字符。而1个 ASCII 字符,大小是 1B,所以,如果按纯文本保存 30亿个字母(单链),就是30亿字母 = 3,000,000,000 B = 3 GB。
- 理论上应该只有25条序列信息(Chr1:22,X,Y,ChrM)。但是在实际下载的文件中,序列数量远远不止这些。
这是由于参考序列一般是通过二代测序产生的,测得的短Read片段拼接、组装成基因组的染色体序列,需要经历contigs与scaffolds两个过程。在拼接过程中会产生额外的scaffolds信息。
这些scaffolds序列主要可以分为三类:
- Unlocalized scaffolds(xxxx_random):知道这些scaffolds在哪条染色体上,但不知道其在染色体的具体位置及方向,其命名规则为
chr{chromosome number orname}_{sequence_accession}v{sequence_version}_random, 如:chr11_KI270721v1_random - Unplaced scaffolds(chrUn_xxxxxx):不知道这条scaffolds的所属染色体信息,命名规则为
chrUn_{sequence_accession}v{sequence_version}, 如:chrUn_KI270302v1 - Alternate loci scaffolds(xxx_alt):这一部分主要是人群特异的一些序列,正常参考序列要求在99.9%的人群中一致,但存在部分序列是某个人群特异的(如50%是A序列,50%是B序列),这部分序列的确存在但又不是参考序列,标记为Alternate loci scaffolds,其命名规则为
chr{chromosome number or name}_{sequence_accession}v{sequence_version}_alt, 如:chr1_KI270762v1_alt
Alternate loci scaffolds为hg38版本基因组新添类型Sequence,此前hg19版本还没有。
基因组结构
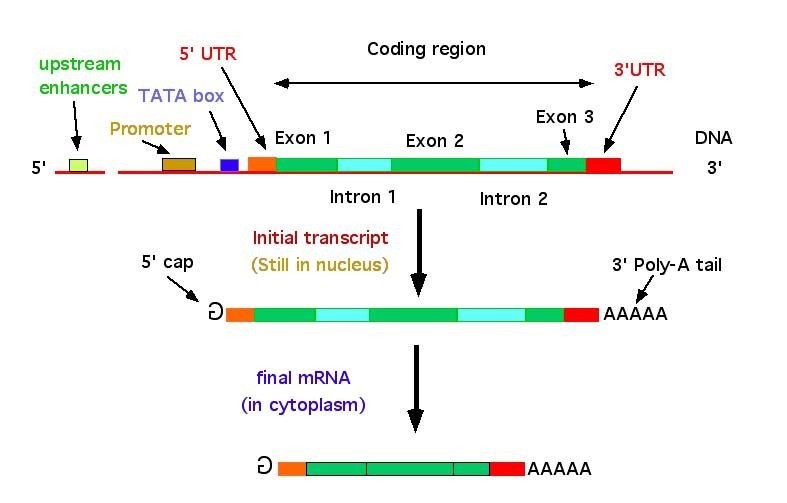
基因 DNA可分为编码区和非编码区:编码区可转录为 mRNA 并最终翻译成蛋白质;非编码区上具有基因表达的调控元件。
- 编码区:在转录的过程,从DNA编码区的5’端开始转录生成preRNA,然后进一步加工修饰剪切得到成熟mRNA,进行后续的翻译。
- 外显子:在preRNA 经过剪切或修饰后、被保留的DNA部分。
- 起始密码子(Start Codon):是mRNA上开始合成蛋白质的密码子,也是第一个被核糖体翻译的mRNA密码子。通常为AUG。
- 终止密码子(Stop Codon):代表核糖体翻译的终止。通常为UAG、UAA、UGA。
- UTR(untranslated region):属于外显子部分。即外显子也包含非编码区域。
- 位于5’端的UTR称为5’UTR, 从mRNA起点的甲基化鸟嘌呤核苷酸帽延伸至AUG起始密码子。
- 与5’UTR上游的第一个碱基相对应DNA链上的碱基称为TSS(Transcription start sites)
- 位于3’端的UTR称为3’UTR,为mRNA的结束部分,从编码区末端的终止密码子延伸至多聚A尾巴(Poly-A)。
- 与3’UTR下游的最后一个碱基相对应DNA链上的碱基称为TTS(Transcription termination sites)
- 位于5’端的UTR称为5’UTR, 从mRNA起点的甲基化鸟嘌呤核苷酸帽延伸至AUG起始密码子。
- CDS(Coding sequence):包括mRNA中从5’UTR后的起始密码子开始到3’UTR前的终止密码子的实际编码蛋白序列
- ORF(Open reading frame):从一个起始密码子开始到一个终止密码子结束的一段序列
CDS一定是ORF,ORF不一定是CDS
- Transcript转录本:一条基因通过可变剪切机制可转录形成的一种或多种可供编码蛋白质的成熟的mRNA。
- ORF(Open reading frame):从一个起始密码子开始到一个终止密码子结束的一段序列
- 在最终成熟mRNA的上下游两端修饰有特殊的结构,分别是5’ cap帽子与 3’ Poly-A尾巴。
Poly-A尾是mRNA’区别于其它non-coding RNA的主要标志
- 非编码区:位于DNA序列上下游的non-coding区域含有调控基因表达原件
- 启动子Promoter:DNA分子上能与RNA聚合酶结合并形成转录起始复合体的区域,位于TSS位点上游的100~1000碱基序列。
- 终止子Terminator:给RNA聚合酶提供转录终止信号的DNA序列
- 增强子Enhancer:可以蛋白质结合的小段DNA,从而加强所调控基因的转录作用。可以位于靶基因的上游/下游,距离也可以很远。
参考基因组下载
参考基因组可以从NCBI、ENSEMBL、UCSC等网站下载,此外gencode网站提供了最新最全的人类和小鼠的基因组序列和注释信息。iGenomes网站提供了较为全面的各版本参考序列构建好的注释文件和各类比对软件的索引文件,可直接下载使用。